24.12.2014
Для работы с биржей ММВБ по протоколу FAST потребовалось использовать протокол IGMPv3 (биржа с v2 не работает), однако винда хоть убей посылает IGMPv2 и все.
Единственное что можно сделать, прописать в реестре здесь:
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Tcpip\Params
ключ
и тогда вроде должно заработать
28.11.2014
Случилась тут необходимость, обновить в mongodb некоторые записи, на основе их же полей – фактически разбить одно поле на два. StackOverflow дал одну идею, которую я решил законспектировать на будущее
db.person.find().forEach( function ( elem )
{
db.person.update(
{
_id: elem._id
},
{
$set:
{
name: elem.firstname + ' ' + elem.lastname
}
} );
} );
17.10.2014
Натолкнулся тут на интересный манифест по принципам разработки больших систем. Потрудился его перевести и представляю его здесь. Если вы владеете английским языком – то лучше почитайте его в оригинале. Для всех остальных, перевод ниже.
Организации, работающие в разных областях деятельности независимо находят сходные паттерны построения информационных систем. Системы, построенные на этих паттернах, обладают большей надежностью, более живучи, более гибкие и лучше позиционируются для решения современных задач.
Это происходит потому, что требования к приложениям радикально изменились в последние годы. Всего лишь несколько лет назад большое приложение могло состоять из пары десятков серверов, время ответа измерялось в секундах, время технических работ могло измеряться часами а данные умещались в несколько гигабайт. Сегодня приложения развернуты везде, где только можно – от мобильных устройств до облачных кластеров с тысячами многоядерных процессоров. Пользователи же ожидают мгновенного ответа от сервера и 100% аптайма. Данные теперь измеряются в петабайтах. Запросы сегодняшнего дня просто не могут быть удовлетворены вчерашними архитектурами.
Мы верим, что требуется сбалансированный подход к архитектуре систем, и мы верим, что все необходимые аспекты уже открыты порознь: нам требуются системы, которые обладают качествами отзывчивости (Responsive), живучи (Resilient), гибкие (Elastic) и основываются на сообщения (Message Driven). Мы называем такие системы «Реактивными» (Reactive Systems).
Такие системы более гибкие, менее связные и масштабируемые. Это упрощает их разработку и развитие. Они более устойчивы к нештатным ситуациям, а когда что-то непредвиденное все-таки случаются, они легко восстанавливаются а не приводят к катастрофе. Реактивные системы обеспечивают пользователю эффективную интерактивную обратную связь.
Реактивные системы:
Отзывчивы (Responsive): Система отвечает настолько быстро, насколько это возможно. Отзывчивость – это краеугольный камень удобных и полезных в использовании систем, но кроме этого, отзывчивость также означает то, что проблемы могут быть быстро диагностированы и эффективно устранены. Отзывчивые системы сфокусированы на обеспечении быстрого и логичного ответа, тем самым формируя верхнюю границу для качества обслуживания. Согласованное ответ в свою очередь упрощает обработку ошибок, сборку и интерфейс пользователя, поощряет дальнейшее взаимодействие.
Живучи (Resilient): Система остается отзывчивой даже в случае отказа. Это правило применяется не только для высокодоступных критичных систем, любая «неживучая» система при сбое станет неотзывчивой. Живучесть обеспечивается репликацией, включением (containment), изоляцией и делегированием. Сбои могут случиться в любом компоненте системы, поэтому изоляция компонентов друг от друга позволяет всей системе оставаться в работоспособном состоянии, даже в случае когда произошел сбой в отдельном компоненте и происходит операция восстановления. Восстановление компонента делегируется другому (внешнему) компоненту, а высокая доступность обеспечевается через резервирование там, где необходимо. Клиент компонента не должен задумываться о том, как действовать в случае его отказа.
Гибки (Elastic): Система должна оставаться отзывчивой под различными нагрузками. Реактивные системы должны реагировать на изменение нагрузки увеличением или уменьшением задействованных ресурсов. Это в свою очередь требует отсутствия ключевых точек или «бутылочных горлышек», что позволяет распределять (shard) или реплицировать (replicate) компоненты, и распределять нагрузку между ними. Реактивные системы должны быть предсказуемыми, алгоритмы масштабирования должны предоставлять все необходимые показатели работоспособности. Такие системы обеспечивают экономию при работе на обычном (не специальном) оборудовании и программных платформах.
Основываются на сообщениях (Message Driven): Реактивные системы основываются на асинхронном обмене сообщениями для обеспечения слабой связности между программными компонентами, изоляции, прозрачности местоположения и дают инструменты для делегирования обработки ошибок через ошибочные сообщения. Благодаря явному обмену сообщениями становится возможным организация балансировки нагрузки, эластичности и управления потоком путем мониторинга и управления потоком очередей сообщений. Прозрачность местоположения сообщений как параметр коммуникации позволяет управлять сбоями одними и теми же методами, вне зависимости от того, работает система на кластере или на отдельном хосте. Неблокирующее взаимодействие позволяет потреблять ресурсы только в периоды активности, что в свою очередь ведет к меньшей перегрузке системы.

Большие системы состоят из маленьких и поэтому зависят от реактивных свойств своих составляющих. Если система построена на реактивных принципах, то это означает что эти принципы применяются на всех уровнях построяния этой системы. Самые большие системы в мире основываются на этих принципах и служат целям миллионов людей по всему миру ежедневно. Пришло время применять эти принципы с самого начала разработки систем, вместо того, чтобы каждый раз открывать их снова.
Подписать манифест можно тут.
02.10.2014
Давненько я сюда не писал ничего технического, настало время заполнить сий пробел. Считаю важным зафиксировать здесь несколько заметок о технологии RAII (Resource Acquisition Is Initialization, получение ресурса есть инициализация). Еще информацию об этой технологии на просторах англоязычного интернета можно найти по названию Scoped-Based Resource Management (SBRM), по русски это будет звучать как-то так – управление ресурсами на основе области видимости.
Технология RAII достаточно часто используется и является важной технологией управления временем жизни ресурсов. Управление осуществляется с использованием вспомогательного объекта, в котором ресурс выделяется в конструкторе, а освобождается в деструкторе.
Давайте проиллюстрируем важность и удобство техники на примере.
Например, у нас есть функция, которая получает мьютекс в начале и освобождает его в конце:
void foo( Mutex& mutex)
{
mutex.acquire( );
// выполняем какой-нибудь код
mutex.release( );
}
Позже, может понадобится добавить досрочный выход из функции по какому-нибудь условию. Пока функция небольшая по размерам, не проблема увидеть, что функция получается мьютекс и освобождает его в конце, поэтому необходимо добавить освобождение мьютекса при досрочном выходе:
void foo( Mutex& mutex )
{
mutex.acquire( );
// выполняем какой-нибудь код
if ( shoudExit )
{
// неплохо бы сделать следующее
mutex.release( );
return;
}
// выполняем какой-нибудь код
mutex.release( );
}
По прошествии длительного времени (год, например) функция разрастается и начинает занимать много строк кода. В процессе роста было добавлено много досрочных выходов, но освобождение мьютекса всегда добавлялось. Однажды, над кодом начинает работать новый человек, он решает добавить очередной досрочный выход… Из-за больших размеров функции мьютекса он может и не увидеть:
void foo( Mutex& mutex )
{
mutex.acquire( );
// очень много строк кода
if ( newShouldExit )
{
// опаньки ...
return;
}
// очень много строк кода
mutex.release( );
}
Из примера видно, что такая техника управления ресурсами очень чувствительна к человеческой ошибке. Поэтому в таких случаях целесообразно применять RAII. Согласно стандарту С++ если мы определяем объект на стеке, его конструктор всегда будет выполнен в процессе инициализации, а деструктор в момент выхода из зоны видимости, то есть при return. Поэтому давайте использовать это соглашение в своих целях для управления ресурсами. Для начала напишем вспомогательный класс для автоматического получения и освобождения мьютекса:
class MutexLock
{
public:
MutexLock( Mutex& mutex )
: _mutex( mutex )
{
_mutex.acquire( );
}
~MutexLock( )
{
_mutex.release( );
}
private:
Mutex& _mutex;
}
Все что требуется – это получить мьютекс в начале нашей функции, и нет больше нужды беспокоиться об его освобождении перед каждым возвратом из функции, потому что об освобождении позаботится деструктор:
void foo( Mutex& mutex )
{
MutexLock lock( mutex );
// очень много строк кода
if ( newShouldExit )
{
// теперь нет необходимости освобождать мьютекс здесь
return;
}
// очень много строк кода
if ( shouldExit )
{
// и здесь тоже не надо
return;
}
// очень много строка кода
// и в конце также не надо
}
Эту технику можно использовать в разных сценариях. Например, если в начале функции выделяется память из кучи, и требуется, чтобы память освобождалась в момент выхода из функции, можно использовать умные указатели STL. Ниже приведен скелет реализации умного указателя с использованием обозначенной техники:
template < typename T >
class SmartPointer
{
public:
SmartPointer( T* ptr )
: _ptr( ptr )
{
}
~SmartPointer( )
{
delete _ptr;
}
T& operator * ( )
{
return *_ptr;
}
T* operator -> ( )
{
return _ptr;
}
private:
T* _ptr;
}
Наша функция в свою очередь будет выглядеть так:
void foo( )
{
// выделяем память
SmartPointer ptr( new MyClass( ) );
// очень много строк кода
// это работает правильно, т.к. мы переопределили оператор ->
ptr->DoSomething( );
if ( shouldExit )
{
// память автоматически очищается в деструкторе
return;
}
// очень много строк кода
// память автоматически очищается здесь тоже
}
С памятью есть еще один интересный пример. Иногда требуется неким образом занять всю доступную память при запуске. Далее мы будем использовать эту память по своему усмотрению с помощью технологии placement new. Соответственно куски такой «сырой» превыделенной памяти мы назовем контекстами памяти. Соответственно мы имеем глобальный набор таких контекстов, после чего мы решаем, из какого контекста будет возвращен указатель на «выделенную» память.
Если дальше необходимо использовать какой-то контекст в рамках области видимости функции, то опять наблюдается уже знакомый паттерн:
class MemoryChunkUse
{
public:
MemoryChunkUse( MemoryChunk& chunk )
: _chunk( chunk )
{
UseMemoryChunk( chunk );
}
~MemoryChunkUse( )
{
ReleaseMemoryChunk( chunk );
}
private:
MemoryChunk& _chunk;
}
Функция будет выглядеть так:
void foo( )
{
// используем контекст
MemoryChunkUse useChunk( GRAPHICS_MEMORY_CHUNK );
// очень много строк кода
if ( shouldExit )
{
// здесь контекст памяти будет автоматически освобожден
return;
}
// очень много строк кода
// здесь контекст памяти также будет освобожден
}
С помощью технологии RAII вы заставляете компилятор освобождать ресурсы за вас, причем практически бесплатно. Круто, не так ли?
23.05.2014
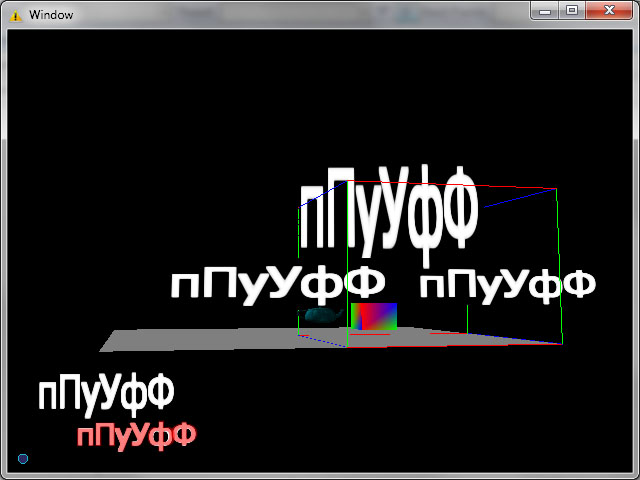
После победного “да!” я решил нарисовать что-то посложнее. Например “пулѣ!” или “пПуУфФ” (который кстати показал всю ущербность расстановки букв). Однако не пулять, не пуф не дали правильного эффекта. Загрузив GIMP и сравнив то что получается в графическом редакторе стало ясно, что полный ахтунг. Увы, скринов не сделал поэтому не покажу. Но было не очень хорошо, или даже “очень не”.
Проблем оказалось несколько. Первая состояла в том, что текстурные координаты я назначаю не совсем правильно. Фактически либо портилось форматное соотношение буквы, либо, если следовать размерам глифа из шрифта не получался мягкий контур, либо нарушался отступ между буквами. Вторая проблема заключалась в неправильной задаче вершинных координат, которые, вкупе с ошибкой в текстурных, приводили к огромному отступу между буквами (кстати, на скринах с “да!” предыдущего поста эти отступы хорошо видны).
Вооружившись листочком я начал искать корень зла (да, кстати он равен примерно 28). В итоге нашел. Текстурные координаты надо выбирать так, чтобы кроме глифа в нужный прямоугольник влезло еще немного пустого пространства (благо метрики шрифта это вполне позволяют), тогда не будет обрезок. Но самое главное, этот запас также надо проецировать и на вершинные координаты. Упражнения с математикой дали результат. Буквы нарисовались правильно, даже сравнение в GIMP’е это подтвердило. Но появилась новая проблема, хотя и понятная сразу – z-fighting. Ввиду дополнительного допуска, прямоугольники букв стали перекрываться. Но z-fighting в этом случае решается быстро – достаточно развести буквы по глубине и вуаля – z-fighting побежден. Кстати, для экранных координат оказалось достаточно значения 0.0001, для мировых – 0.001.
Ну и напоследок скрин. Белые буквы – то что получается в движке, красные (с 50% прозрачностью) наложены в GIMP’е – для сравнения. По моему – отлично!