Продолжаем рисовать буковки, теперь и Юникод!
03.05.2014После того, как удалось нарисовать букву “g”, следующим логичным шагом было бы нарисовать буквы русские, т.е. Юникод. Однако возникает одна небольшая проблема. Имя ей – UTF-8, а точнее – отсутствие встроенных в С++ нормальных механизмов работы с unicode (wchar_t не в счет – это не совсем Юникод). Пока для целей тестирования были взяты определенные коды символов (буквы ё и ѣ), получены их utf-8 коды (0xd1 0×91 и 0xd1 0xa3 соответственно) и уже по этим кодам рассчитаны необходимые данные.
В дальнейшем же при визуализации текста стоит решить, какого подхода придерживаться. Можно использовать UTF-8 и const char, либо wchar_t. Первый вариант дает более компактное представление, но функции strcmp, strlen и т.д. будут работать неправильно. С точки же зрения wchar_t функции будут работать правильно, но в Windows sizeof(wchar_t) = 2, что не совсем Юникод, и кроме того, например, китайские символы – это три байта даже в UTF-8. Поэтому хочется const char и UTF-8, посмотрим что получится.
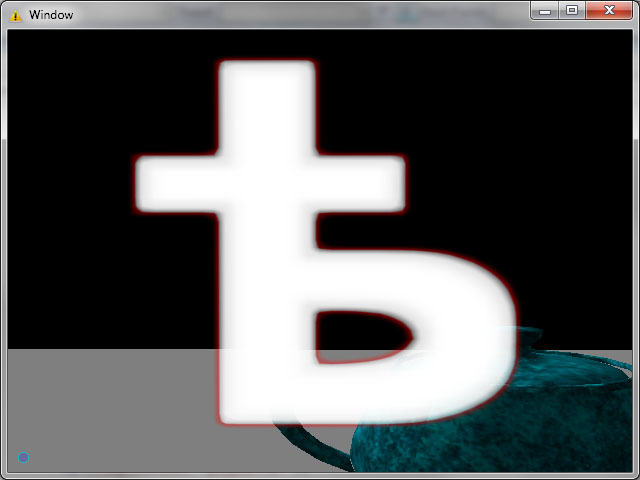
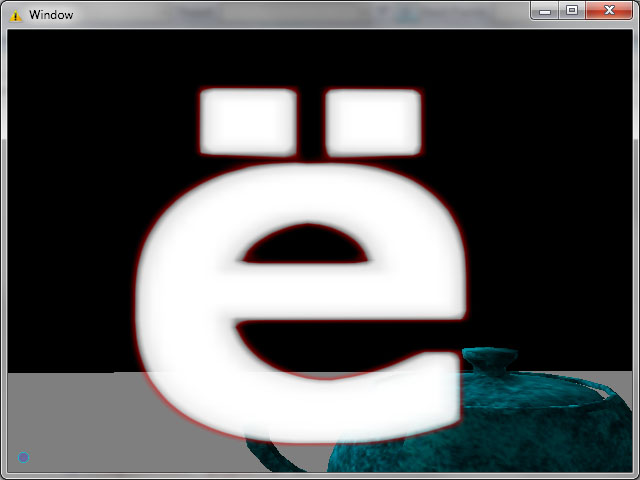
А теперь что получилось, буквы взяты специально экзотические
“ё”
“ѣ” (ять, да-да тот самый ять :) )